
Event
In kritischen Prozessen zählt bei einer KI-Zusammenfassung nur eines: ob sie vollständig und faktisch korrekt ist. Klassische Metriken messen aber vor allem Ähnlichkeit. Ob eine Information fehlt oder erfunden wurde, entgeht ihnen oft.
Liliya Imasheva aus unserem Team hat dafür eine Validierungs-Pipeline gebaut und auf der Conf42 Large Language Models 2026 vorgestellt. Ihr Ansatz verbindet klassische Scores mit einem Judge-Modell, das jede Zusammenfassung nach denselben Kriterien bewertet, die auch ein menschlicher Experte anlegen würde. So entsteht eine automatisierte Qualitätssicherung, die auch einem Audit standhält.
Die Aufzeichnung des Vortrags steht hier zur Verfügung.
Event

Perelyn stellte auf der IOCMA 2026 der Konferenz unser Verfahren vorgestellt, das Graphdaten wie Lieferketten oder Netzwerke so transformiert, dass KI-Modelle auch über große Distanzen hinweg verlässlicher daraus lernen.
Event

Perelyns Anton Steuer stellte auf der Helmholtz AI Konferenz sein Verfahren zur Erforschung kultureller Werte in Large Language Models vor, welches nicht nur die Antworten der Modelle liest, sondern direkt in ihre internen Repräsentationen schaut
News
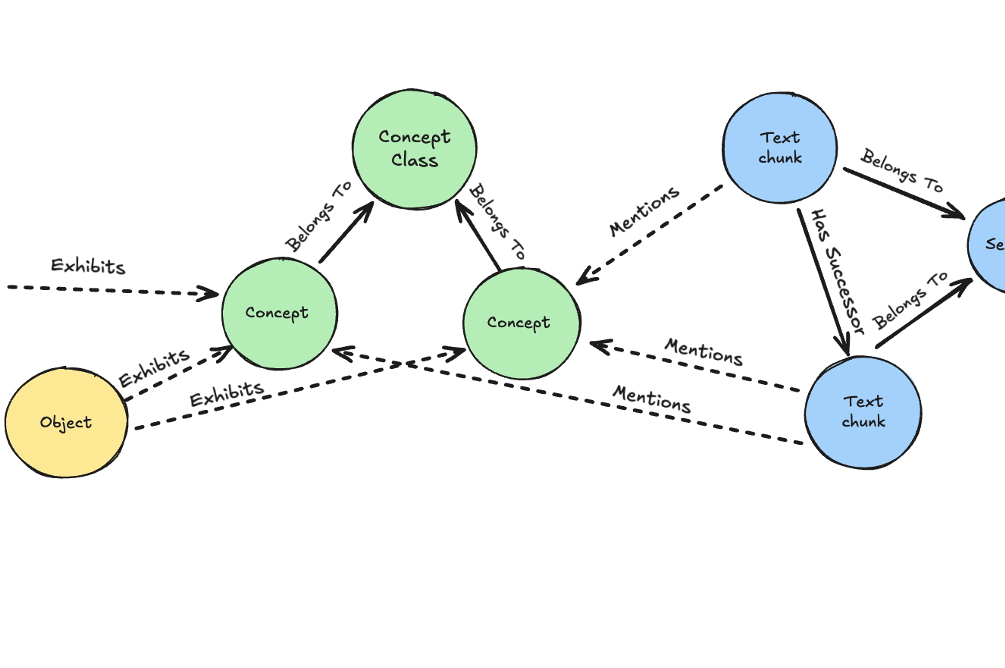
Die Beiträge des Workshops „Knowledge Management" auf der KI2025 sind als Sammelband veröffentlicht worden. Darunter ein Paper unseres Teams über ein neuartiges Wissensgraph-basiertes RAG Verfahren entwickelt für treffsichere, nachvollziehbare Antworten bei weniger Fehlern und niedrigeren Kosten.