News
Damit eine KI verlässlich mit den eigenen Unternehmensdaten wie Verträgen, Akten oder Richtlinien arbeiten kann, braucht sie ein Verfahren, das ihr zu jeder Frage die passenden Textstellen heraussucht und mitgibt.
Das Problem: Übliche Verfahren suchen diese Textstellen nur nach oberflächlicher Ähnlichkeit aus und liefern dadurch oft unvollständige oder aufgeblähte Eingaben.
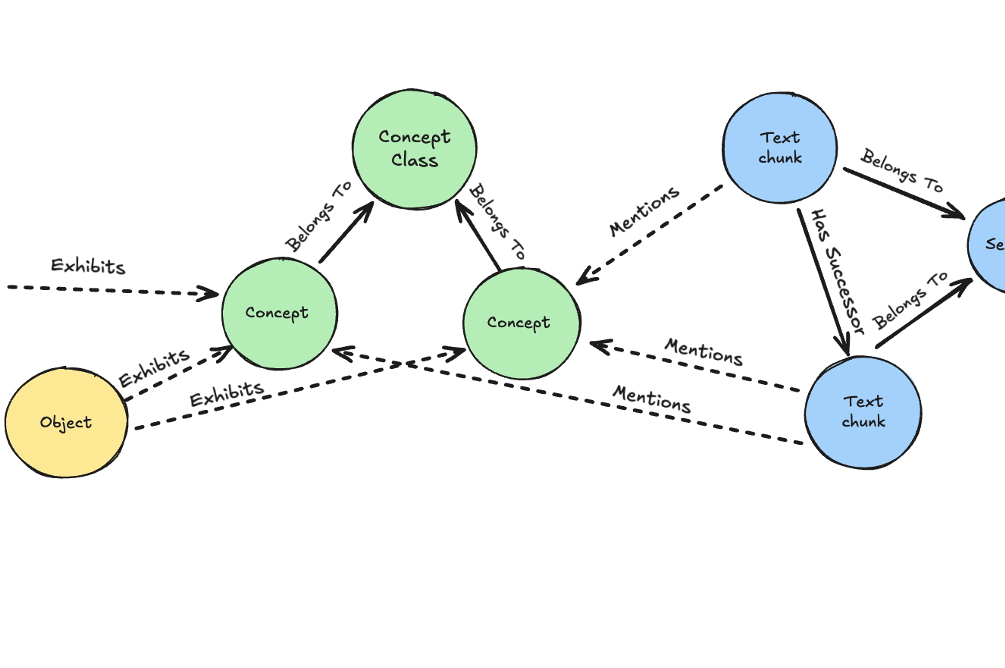
Perelyn hat auf Basis eines neuartigen dreiteiligen Wissensgraphen ein Verfahren entwickelt, welches die Suche stattdessen an klar definierte Fachbegriffe hängt und somit in der Lage ist, kürzere, treffsicherere und nachvollziehbare Eingaben zu erzeugen, was direkt weniger Fehler, niedrigere Kosten und überprüfbare Quellen bedeutet.
Das Verfahren wurde im Rahmen des Workshops „Knowledge Management" auf der KI 2025 in Potsdam vorgestellt und ist jetzt im Sammelband erschienen.
Research at heart. Business in mind.
Hier der link zum Sammelband
Event

Liliya Imasheva stellte auf der Conf42 Large Language Models 2026 eine Validierungs-Pipeline zur Bewertung von KI-Zusammenfassungen vor.
Event

Perelyn stellte auf der IOCMA 2026 der Konferenz unser Verfahren vorgestellt, das Graphdaten wie Lieferketten oder Netzwerke so transformiert, dass KI-Modelle auch über große Distanzen hinweg verlässlicher daraus lernen.
