
Event
In critical processes, only one thing matters for an AI summary: whether it is complete and factually correct. However, classic metrics primarily measure similarity. They often miss whether information is missing or fabricated.
Liliya Imasheva from our team built a validation pipeline for this purpose and presented it at Conf42 Large Language Models 2026. Her approach combines classic scores with a judge model that evaluates each summary according to the same criteria a human expert would apply. This creates automated quality assurance that can also withstand an audit.
The recording of the presentation is available here .
Event

At the IOCMA 2026 conference, Perelyn presented our method, which transforms graph data such as supply chains or networks so that AI models can learn more reliably from it, even over long distances.
Event

Perelyn presented a method at Helmholtz AI Conference for researching cultural values in Large Language Models, which not only reads the models' responses but directly examines their internal representations.
News
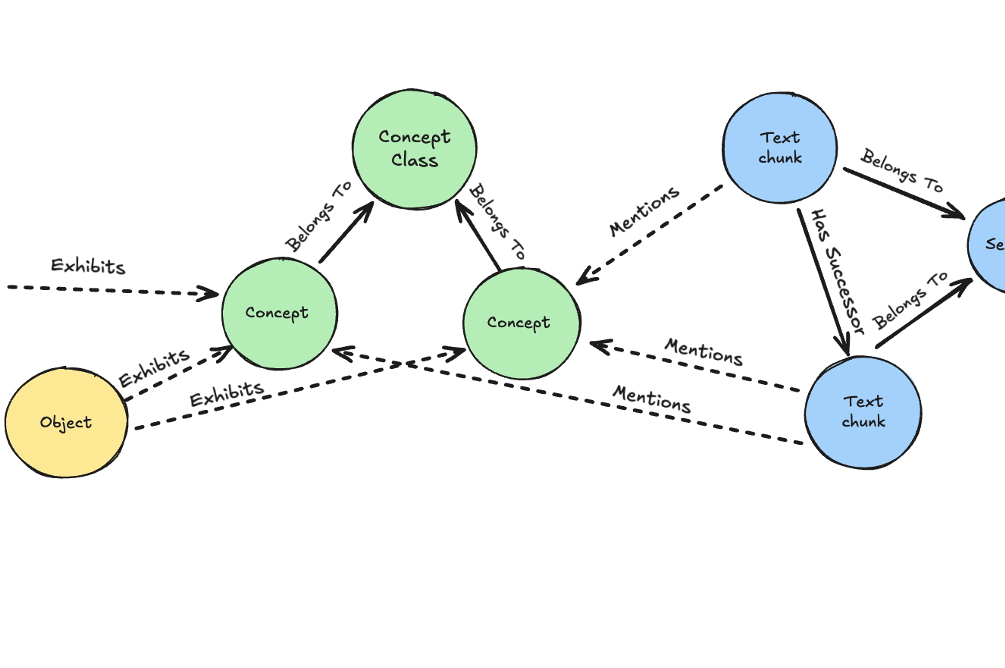
The contributions from the "Knowledge Management" workshop at KI2025 have been published as a collected volume. Among them is a paper by our team on a novel knowledge graph-based RAG method, developed to provide accurate, verifiable answers with fewer errors and lower costs.